
�x��Kettle�_ԴETL���߽̳�
�r�g��2019-08-20 17:34:08 ���ߣ�Dorise �g�[����96
�˂�������ˮƽ��u��ߣ����|����õ��M���ͬ�r�����������M���S֮���ӣ���X�ѽ��ɞ��҂������к����в���ȱ�ٵ�һ���֣���X����һЩܛ����ϵ�y������ȽM�ɣ���ô�҂������Ҫ����X���õ�ʹ�ã��҂���회��@Щ�����˽⣬����С���͎��I���һ����W�������Kettle�_ԴETL���ߣ�
Kettle��һ��Java������ETL���ߣ���4.2�汾�_ʼ����Apache Licence 2.0�f�h�����·������7.1����Kettle��2006����������_Դ��BI��˾Pentaho����ʽ�����飺Pentaho Data Integeration�����Q“PDI”����

�x��Kettle�_ԴETL���߽̳̈D1
���ETL����ƫ�ӵĔ������A�Թ��������ȵ��Ŀ���Ñ���������̫���@����ľ��w����ͼ��gҪ�����Ҳ��̫�Pע�Ŀ�_�l������ʹ����ʲô�ӮaƷ�������@����aƷ�ڹ����ԡ������ԡ����Q���ܡ��������r��(��С���t)���ɿ������ԡ����\�S�����Եȷ���ȱ�����w��ָ��Ҫ��ͨ������Ҫ��ͨ�^�����POC�yԇ�x�ͣ��ټ���Kettle���A�����_Դ���M�ģ�����S�༯����/�_�l�����Ŀ�О����빝ʡ�ɱ���äĿʹ�ã��Y���������m���䷴�������ǰ��Ͷ�����ஔ����_�l�����ɱ������ڸ߰����\�S�ɱ����_�����A��Ч�����T���y�¡������P�߶�ʮ������Ŀ��ʩ�����I�������R����Ҫ���Y���x��kettle��ע��Ć��}��
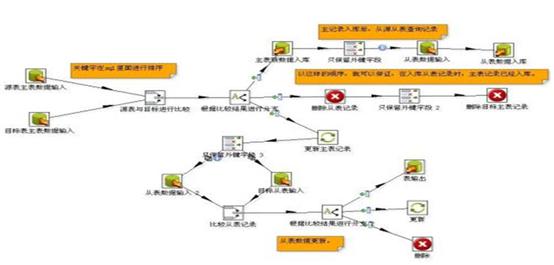
�x��Kettle�_ԴETL���߽̳̈D2
Kettle��֧���r����ͬ���������M��kettle����ʹ��trigger��ʽ�@ȡ������������������Դ�˵đ���ϵ�y��һ�㲻��ͬ��ʹ���@�N�����Ժ��ķ�ʽ������trigger��ʽ�o�����C�Տ��Ƶ������Ժ͕r�g�����ԡ�
Kettle���Q���������_����Ҫ������kettle�����˶�ʮ����ǰ���f��Java�{�ü��g�����΄նࡢ��������Ĉ����£����������^���Ӌ���YԴ�����Q���ܼ����½������ϵ�y�����Ġ�r���F��
Kettle�����c��Ϣ�]��ӛ䛺ͱ��棬�o�����C���c�m�����������Gʧ�ȿɿ���Ҫ��
Kettle��ETL ̎�������cĿ��ݔ������ԏ����µĔ���Ҫ�����������̎�����̵������OӋ���`���Բ���r�g���ںͳɱ��������ӡ��³��F��ELT����T-̎��������ĩ�˔��}��̎�������g�ܘ��ͷ���������ȡ�����d�^���c�D�Q�^�̷��_������������Ҫ��ȫ���͌��r�����������ټ��d�����}����ζ���ڔ��}�Y���OӋ�и������`���ԁ����]�µ�׃�������������Ŀ���\�S���������Ŀ���L�U��С����

�x��Kettle�_ԴETL���߽̳̈D3
�������ӵĮ�������Դ�h�����������N�Pϵ�����������Y�������ǽY�����������Լ�NoSQL��MPP������/�}��ʹ�ƽ�_Hadoop/Kafka�đ��íh����Kettleȱ��������Դ����Ч֧��������
���M���Kettleȱ����Ҫ�Ĕ�������̎���ͱO���\�S�ȹ������ܷ��գ��Ŀ�_�l��/���������Ŀ�ɱ����r�g�ļs���£��y�ڝM���@�������������ɺ��mϵ�y�\�S�|�����Ñ��M��ȵ��½���
����I˽���ƺͻ���Ƶ�Ӌ��h���£�Kettle�Ȃ��y�aƷ��C/S�ܘ��y�ڝM�㘋�����c߅���˵Ĕ������Q����֧���h�̶��Ñ�����ʹ�õ�Ҫ��
���P�YӍ
- ��֦FM����6���������µļm��?
- 10000��˾�C���V�㣺�ε�Ҳ���ڶ��˶��ɣ���...
- ը��С����淨Ԕ�� ����С���ɅR��
- ������APP�ϏV������Ͷ�M����������?
- �ְ��ֽ�������á����۲顱��һ�r�g�l���...
- B612�������o��ͯԒ���X����������
- �y�̾W��ô���̓r�CƱ �y�̓��̓r�CƱ����
- ֪����߅��С���ɣ������@Щ������p������...
- ��������I�Ϳ��ٌ��Ҵ�
- ���FС���ɡ���W���ˆ�?
- ���ȵ؈DAPP�Ă���?�ߵ¡��ٶȺ��vӍ���Ȝy...
- �x��Kettle�_ԴETL���߽̳�
- linux��������̳�
- PDF���ֽ�ļ�����������
- office Acc Microsoft ess�����Խ̳�
- ����������yƷ�O�ܡ�APP���ˣ��䰸���S�ɡ�...
- ���_Airbnb�۱�ӭ2019�����_����
- ��θ��õ�ʹ��PDF�� ���A�[�ϲ�����
- ��θ��õ�ʹ��PDF��������ߵ�Acrobat
- ���ȵ؈DAPP�Ă���?�ߵ¡��ٶȺ��vӍ���Ȝy...